System Design Interview Part 1

# What is System Design Interview about
System design interviews is all about - thought process. Its more than just connecting servers and databases. System design requires an engineer to analyze a problem and provide the most efficient solution by determining the best ways to move, store, and transform data.
# The High-Level App Architecture & Scaling
The lifecycle of an application begins with the developer building code. Once the code is ready, it is deployed to a server, which then interacts with storage systems (such as databases) and external APIs to fulfill user requests.
As a system grows, its architecture needs to adapt to handle more traffic. That’s where scaling comes in.
-
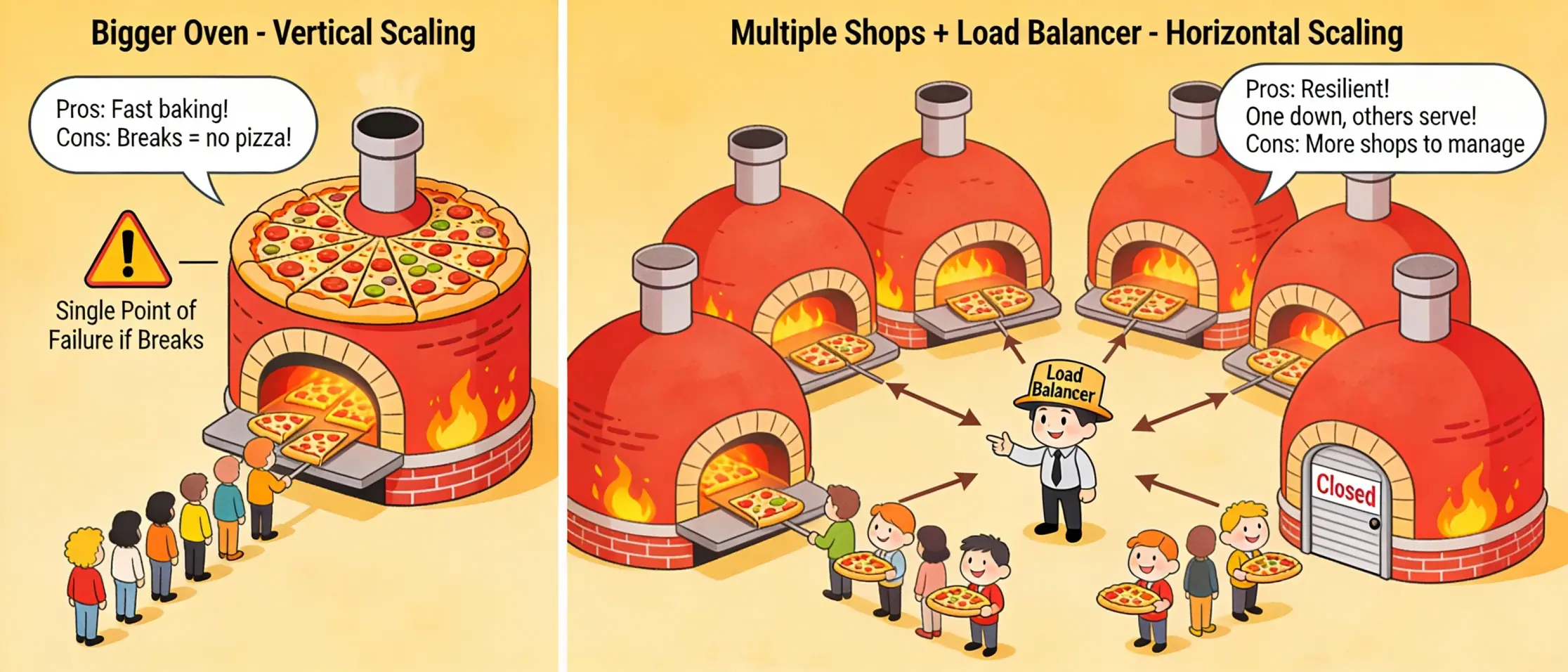
Vertical Scaling: This involves upgrading the hardware of a single server machine, such as increasing its CPU or Storage capacity. While this can improve reliability, it often results in a single point of failure.
-
Horizontal Scaling: This involves adding several servers to the infrastructure and using a load balancer to distribute traffic among them.
Imagine a small pizza shop. Horizontal scaling means opening a several more pizza shops nearby and having someone (like a load balancer) send customers to the shop with the shortest line. Vertical scaling means getting a faster, more powerful oven so you can bake pizzas quicker. The big oven works well but if it breaks, you can’t make pizzas. With multiple shops, even if one closes, the others can still serve customers.
# System Health: Logging, Metrics, and Alerts
A production-ready system requires constant monitoring to ensure it functions correctly. To achieve this, developers rely on three key supporting services:
- Logging Servers: These are used to store logs from applications to track specific errors and issues.
- Metrics Services: These services provide logging analytics, giving developers a clear view of how the server is performing in real-time (ex: grafana)
- Alerts Services If a metric reaches a dangerous threshold. For example, if a CPU hits 95% - the service will automatically notify the developers so they can take action.

# Defining "Good" Design
How do we measure if a design is successful? It usually comes down to how the system handles failure and uptime.
A well-designed system is one that remains available and reliable even in the face of failures.
- Availability. We often measure this by looking at logs and metrics.
- Reliability. It reflects the system’s ability to keep working during events like updates, crashes, or DDoS attacks.
Achieving this level of reliability requires fault tolerance and redundancy, meaning the system can continue running even when individual components fail. Techniques like vertical scaling help build this resilience, improving both reliability and overall system health.
# Fault Tolerance and Redundancy
A system is "tolerant" to "faults" if it can continue to operate even when a component fails. This is achieved through redundancy - having extra components available so that if one fails, others can help. Vertical scaling is one method used to achieve this fault tolerance and address reliability issues.
# Performance Metrics: Throughput vs. Latency
To optimize the user experience, developers must balance two critical performance metrics.
- Throughput: This measures the capacity of the server, or how many requests it can handle in a specific timeframe (e.g., 10 requests per second)
- Latency: This measures the time it takes for an individual request to complete.
High latency is often caused by network issues or the physical distance of the user. To combat this, developers use CDNs (Content Delivery Networks) to reduce the distance between the data and the user, thereby lowering latency.
# Summary
- System Design as a Thought Process: Focuses on analyzing problems to plan efficient ways of moving, storing, and transforming data.
- Core Architecture: Involves developers writing code, deploy to servers that interact with storage systems and external APIs.
- Vertical Scaling: Upgrading a single server’s hardware (CPU, GPU).
- Horizontal Scaling: Adding multiple servers with a load balancer to share traffic.
- Monitoring and Maintenance: Relies on logging (error tracking), metrics (performance analytics), and alerting (threshold notifications) to keep systems healthy.
- Reliability & Fault Tolerance: Ensured through redundancy so other servers can take over if one fails.
- Throughput: Number of requests handled per unit time.
- Latency: Time to complete a single request, reduced using CDNs.